实战Spark3 实时处理,掌握两套企业级处理方案【已完结 MK459】

-
第1章 【项目启动】项目背景及架构分析
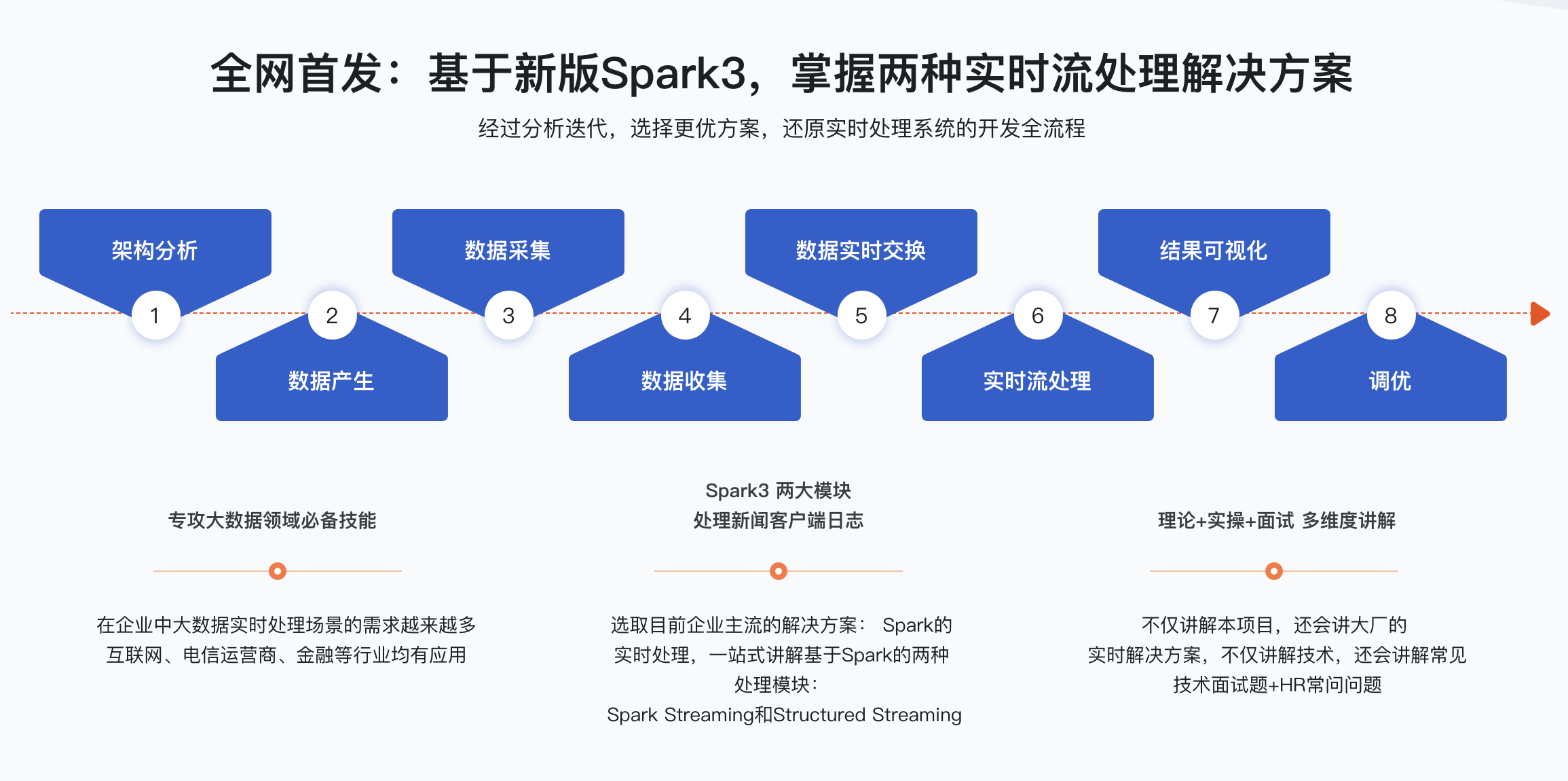
本章将介绍实战项目背景、数据流,并让大家对知晓在实际项目中应如何进行技术的选型以及项目架构的迭代过程。
- 1-1 课程概览试看
- 1-2 ***学前必读***(助你平稳踩坑,畅学无忧,课程学习与解决问题指南)
- 1-3 课程目录
- 1-4 项目目的
- 1-5 项目流程
- 1-6 技术选型
- 1-7 项目总体架构
- 1-8 项目架构V1版本
- 1-9 项目架构V2版本
-
第2章 【环境部署】基础开发环境搭建
工欲利其事必先利其器,本章重点介绍项目实战中要使用的大数据框架的部署,基础不是很牢固的同学要认真看哦。
- 2-1 课程目录
- 2-2 OOTB环境的使用介绍
- 2-3 JDK部署
- 2-4 Scala部署
- 2-5 Maven部署(一定要仔细听)
- 2-6 Hadoop配置
- 2-7 Hadoop格式化&启停
- 2-8 ZK部署
-
第3章 【数据采集】构建日志服务器
本章节讲解项目中要使用的数据是如何产生及落地的。我们将采用Spring Boot开发日志服务,将访问日志通过日志服务落地到日志服务器磁盘。
- 3-1 课程目录
- 3-2 数据产生和上报流程
- 3-3 构建多Module工程
- 3-4 快速构建第一个Spring Boot应用程序
- 3-5 SpringBoot热部署
- 3-6 关于Annotation的补充
- 3-7 yml配置文件的使用
- 3-8 开发日志服务Controller
- 3-9 客户端上报日志功能开发
- 3-10 客户端与日志服务器联调测试
- 3-11 客户端日志上报到日志服务器并落盘
- 3-12 日志服务部署到服务器上运行并联调
- 3-13 对接项目数据到日志服务器
- 3-14 作业
-
第4章 【数据收集】基于Flume构建分布式日志收集
本章节讲解如何采用Flume来完成日志数据的收集工作。讲解Flume在生产上不同的场景的经典部署方案、Flume Agent的不同选型及配置、在生产环境Flume高可用的使用以及如何基于Flume进行二次开发,并使用Flume收集上一个章节中产生的日志数据。…
- 4-1 课程目录
- 4-2 产生背景
- 4-3 采集和收集的区别
- 4-4 Flume概述
- 4-5 Flume版本迭代
- 4-6 Flume体系架构与三大核心组件
- 4-7 业界数据收集框架对比试看
- 4-8 Flume部署
- 4-9 Flume Agent编程案例
- 4-10 Event
- 4-11 Flume经典部署方案
- 4-12 Flume收集文件数据到HDFS需求分析
- 4-13 Flume收集文件数据到HDFS实现
- 4-14 Flume收集文件夹数据到HDFS
- 4-15 TailDirSource实战(非常重要)
- 4-16 Flume拦截器二次开发需求分析
- 4-17 Flume自定义拦截器开发(非常重要)
- 4-18 Flume自定义拦截器Agent配置(非常重要)
- 4-19 Flume自定义拦截器功能测试
- 4-20 使用Flume收集日志服务器落地的日志数据
- 4-21 面试题谈谈你对Flume高可用的看法(重要)
- 4-22 本章作业
- 4-23 【夯实学习成果,攻克面试官】Flume面试题
-
第5章 【消息队列】基于Kafka构建实时数据交换
Kafka是大数据项目选型中使用的最多的消息队列框架,本章节要掌握Kakfa的部署、使用命令行和API的方式进行Kafka的相关操作,分析Kafka的数据存储是什么样,并重点分析一个高频面试题ack的使用。最终完成,使用Kafka对接上一个章节Flume数据到的数据。…
- 5-1 课程目录
- 5-2 Kafka概述
- 5-3 Kafka核心术语(重要)
- 5-4 Kafka单Broker部署及使用
- 5-5 Kafka多Broker部署及使用
- 5-6 容错性测试
- 5-7 Kafka Producer API编程
- 5-8 Kafka Consumer API编程(重要)
- 5-9 Kafka对接Flume收集的数据
- 5-10 对接项目数据到Kafka
- 5-11 Kafka数据存储(非常重要)试看
- 5-12 面试题谈谈你对acks的看法(非常重要)
- 5-13 【夯实学习成果,攻克面试官】Kafka面试题
-
第6章 【实时流处理】Spark Streaming核心API及编程初探
本章节会先带领大家知晓SparkStreaming能做什么,快速构建第一个Spark Streaming的应用程序并在本地和打包在服务器上运行,然后重点讲解基于开发Spark Streaming应用程序的核心概念,并详解如何对接socket和HDFS文件系统上的数据进行处理。如何使用Spark Streaming进行状态相关的处理以及整合Spark SQL的使用。…
- 6-1 课程目录
- 6-2 Spark Streaming概述
- 6-3 Spark Streaming宏观角度了解
- 6-4 基于IDEA+Maven构建第一个流处理应用程序
- 6-5 本地功能测试
- 6-6 官网案例解读
- 6-7 Spark部署及服务器端测试
- 6-8 StreamingContext编程注意事项
- 6-9 核心概念DStream
- 6-10 核心概念Input DStream和Receiver
- 6-11 实战之读取文件系统的数据
- 6-12 常用Transformation操作
- 6-13 实战之日志数据过滤RDD方式实现
- 6-14 实战之日志数据过滤transform方式实现
- 6-15 实战之带状态的应用程序开发
- 6-16 常用Output操作
- 6-17 实战之统计结果写入数据库(非常重要)
- 6-18 快速了解Spark SQL进行数据分析
- 6-19 实战之SparkStreaming和Spark SQL的整合使用
- 6-20 面试题之谈谈你对消费语义的认识
- 6-21 【夯实学习成果,攻克面试官】Spark Streaming面试题
-
第7章 【实时流处理】应用Spark Streaming实现数据分析及调优
本章节将讲解使用Spark Streaming进行项目实战。重点分析Spark Streaming如何对接Kafka的数据进行消费以及偏移量的自定义维护管理,使用Spark Streaming进行数据清洗以及项目功能的实现。并且,在完成功能的基础上如何进行其他功能的扩展、常用的调优点以及大数据集群规划。本章节是线上开发以及面试过程中必须掌握的!….
- 7-1 课程目录
- 7-2 项目需求介绍
- 7-3 论Offset对整个实时作业处理结果的影响
- 7-4 图解SparkStreaming整合Kafka offset的管理机制
- 7-5 使用checkpoint维护offset
- 7-6 自定义维护offset的表结构设计
- 7-7 使用ScalikeJDBC对MySQL进行读写操作
- 7-8 Offset的获取及存储注意事项
- 7-9 自定义维护Offset存储实现
- 7-10 自定义维护Offset读取实现
- 7-11 Offset管理封装及作业
- 7-12 数据流打通及日志字段描述
- 7-13 数据清洗功能
- 7-14 功能三需求分析
- 7-15 HBase初探
- 7-16 HBase部署
- 7-17 HBase核心API编程
- 7-18 需求三功能实现
- 7-19 功能四功能实现
- 7-20 功能扩展及实现思路
- 7-21 Spark调优之序列化
- 7-22 调优之序列化在SS中的使用场景
- 7-23 调优之设置合理的Batch Interval
- 7-24 调优之限速
- 7-25 集群规模评估
- 7-26 集群部署进程分布规划
- 7-27 HBase逻辑模型
- 7-28 HBase物理存储模型
- 7-29 HBase架构宏观角度分析
- 7-30 HBase架构组件职责
- 7-31 面试题之HBase寻址机制(重要)
- 7-32 面试题之HBase写数据流程(重要)
- 7-33 面试题之HBase读数据流程
- 7-34 项目打包并运行在YARN上
- 7-35 HBase表及rowkey设计原则
- 7-36 本章总结及作业
- 7-37 【夯实学习成果,攻克面试官】Spark Streaming面试题
-
第8章 【实时流处理】Structured Streaming企业级应用
本章节将介绍Spark中新的流式模块Structured Streaming。通过本章学习,大家会知晓与Spark Streaming的优势体现在哪、掌握Structured Streaming的编程模型以及核心概念、基于EventTime的实时处理方式、对接常用数据源以及Streaming DataFrame编程、对接常用的Sink、Watermark机制和处理延迟数据的解决方案。…
- 8-1 课程目录
- 8-2 SparkStreaming的不足
- 8-3 Structured Streaming概述
- 8-4 快速开发第一个Structured Streaming应用程序
- 8-5 Structured Streaming编程模型
- 8-6 处理EventTime和延迟数据
- 8-7 使用SQL完成统计分析
- 8-8 对接csv数据源数据
- 8-9 对接分区数据源数据
- 8-10 对接Kafka数据源数据
- 8-11 基于EventTime的窗口统计原理详解
- 8-12 基于EventTime的窗口统计功能实现
- 8-13 延迟数据处理及Watermark
- 8-14 File Sink
- 8-15 Kafka Sink
- 8-16 ForeachSink到MySQL
- 8-17 容错语义
- 8-18 【夯实学习成果,攻克面试官】Structured Streaming 实战面试题
-
第9章 【实时流处理】应用Structured Streaming实现数据分析及调优
本掌中将使用Structured Streaming框架来实现Spark Streaming项目中的清洗和统计功能,做到举一反三的功效,使得大家会使用不同的框架来进行相关业务的开发和处理。
- 9-1 课程目录
- 9-2 项目需求
- 9-3 数据清洗
- 9-4 Redis概述及部署
- 9-5 Redis命令行操作快速入门
- 9-6 通过Jedis API操作Redis
- 9-7 将统计结果输出到Redis
- 9-8 打包到服务器运行
- 9-9 调优及作业
- 9-10 【夯实学习成果,攻克面试官】Structured Streaming 面试题
-
第10章 【数据可视化】使用Echarts完成数据展示
本章节将对使用Spark Streaming以及Structured Streaming统计分析的结果进行可视化展示,采用前后端分离,请求后台查询服务接口并通过Echarts进行展示【前端部分采用React封装Echarts,源码随课赠送】。
- 10-1 课程目录
- 10-2 Spring Data概述
- 10-3 Spring Data整合MySQL开发环境准备及实体类开发
- 10-4 Spring Data存取MySQL功能开发及测试
- 10-5 Controller层开发及测试
- 10-6 常用可视化框架介绍
- 10-7 Echarts图形形成方式
- 10-8 Spring Boot整合Echarts快速开发一个可视化展示功能
- 10-9 Spring Data整合HBase开发环境搭建
- 10-10 Spring Data整合HBase查询功能开发及测试
- 10-11 Spring Data整合Redis查询功能开发及测试
- 10-12 可视化项目部署
- 10-13 前后端服务部署及效果演示
- 10-14 前后端交互流程分析
-
第11章 【拓展&经验分享】核心梳理及面试指导
本章节在对课程重难点内容进行总结的同时,重点分享面试过程中HR常考点、准备大数据简历注意要素、以及实时处理在大厂中的应用。
- 11-1 课程目录
- 11-2 HR面试常考点一
- 11-3 HR面试常考点二
- 11-4 HR面试常考题三
- 11-5 HR面试常考点作业
- 11-6 简历编写及面试准备
- 11-7 Spark&NoSQL实时数据处理实践案例分享
- 11-8 课程总结与展望