Spark进阶 大数据离线与实时项目实战【已完结】

-
第1章 课程介绍&学习指南
本章会对这门课程进行说明并进行学习方法介绍。
- 1-1 课程介绍试看
- 1-2 ***学前必读***(助你平稳踩坑,畅学无忧,课程学习与解决问题指南)
-
第2章 Redis入门
Redis是目前最火爆的内存数据库之一,通过在内存中读写数据,大大提高了读写速度。本章将从Redis特性、应用场景出发,到Redis的基础命令,再到Redis的常用数据类型实操,最后通过Java API来操作Redis,为后续实时处理项目打下坚实的基础…
- 2-1 课程目录
- 2-2 Redis概述
- 2-3 Redis特性
- 2-4 Redis应用场景
- 2-5 Redis部署&服务启停&客户端连接
- 2-6 Redis多数据库特性试看
- 2-7 Redis基础命令的使用
- 2-8 Redis数据类型之string
- 2-9 Redis数据类型之list
- 2-10 Redis基本数据类型之set
- 2-11 使用Jedis对Redis进行操作
- 2-12 Redis工具类开发
-
第3章 HBase入门
HBase是一个分布式的、面向列的开源数据库,该技术来源于 Fay Chang 所撰写的Google论文“Bigtable:一个结构化数据的分布式存储系统”。本章将从HBase是什么、有哪些特点出发,到HBase环境部署,到HBase的数据模型,到HBase的操作(命令行&API),为后续离线处理项目的数据存储以及查询打下坚实的基础。…
- 3-1 数据存储现状
- 3-2 HBase是什么
- 3-3 HBase在生态圈中的位置以及列式存储带来的好处
- 3-4 HBase的特点.mp4
- 3-5 HBase vs RDBMS vs HDFS.mp4
- 3-6 HBase的优势
- 3-7 HBase数据模型
- 3-8 JDK环境搭建
- 3-9 Hadoop环境部署(详解一个常见的错误解决方案)
- 3-10 ZooKeeper环境部署
- 3-11 HBase环境部署
- 3-12 HBase shell DDL操作
- 3-13 HBase shell DML操作
- 3-14 HBase API编程之开发前置准备工作
- 3-15 HBase API编程之创建表以及查询表和所有列族
- 3-16 HBase API编程之添加和修改记录
- 3-17 HBase API编程之通过RowKey获取值
- 3-18 HBase API编程之Scan
- 3-19 HBase API编程之Filter
- 3-20 HBase API编程之总结
-
第4章 离线项目实战V1
本章节讲解基于Spark和HBase的离线综合项目实战,从多个框架的整合出发,到使用Spark进行ETL处理然后数据落地到HBase中涉及到的传参、HBase Rowkey的设计,再到性能的初步调优,最后使用Spark整合HBase进行数据的统计分析。本章是基于Spark进行离线处理的重点,务必掌握。…
- 4-1 课程目录
- 4-2 项目背景
- 4-3 项目处理流程.mp4
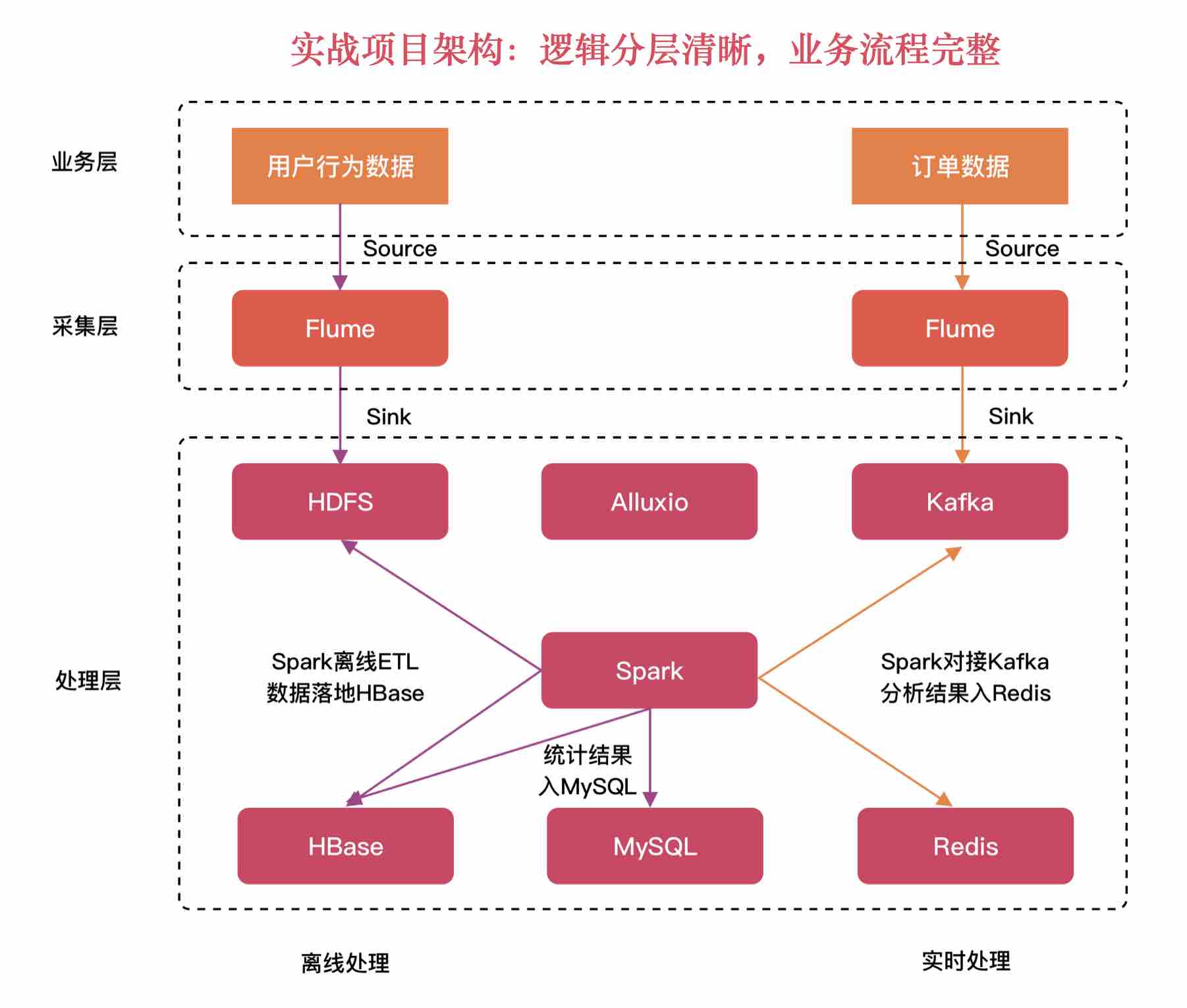
- 4-4 项目离线和实时架构图
- 4-5 明确架构图中每个步骤使用的技术以及职责所在试看
- 4-6 项目指标需求
- 4-7 功能开发之UserAgent解析(掌握如何获取技能)
- 4-8 功能开发之IP解析思路
- 4-9 功能开发之Spark和HBase依赖整合
- 4-10 开发环境依赖使用说明
- 4-11 功能开发之解析日志成DataFrame并为DataFrame添加字段信息
- 4-12 功能开发之将DF内容转成HBase要存储的列
- 4-13 功能开发之整体ETL流程详解及如何传参设计
- 4-14 功能开发之创建HBase表
- 4-15 功能开发之HBase Rowkey设计_1
- 4-16 功能开发之完成ETL数据到HBase落地的全过程
- 4-17 功能开发之完成第一个指标的统计分析
- 4-18 功能开发之完成第二个指标的统计分析
- 4-19 性能优化之缓存的使用
- 4-20 功能开发之统计功能使用DataFrame API以及SQL API来完成
- 4-21 本章小结
-
第5章 离线项目实战优化
本章节将基于前面一个章节的功能实现进行进一步的优化,如何将在需求功能实现的基础之上,进行调优,使得在生产上的执行效率更高。本章将是提升自身综合实力的关键部分,务必掌握。
- 5-1 课程目录
- 5-2 Spark on YARN
- 5-3 Linux时间获取
- 5-4 shell封装Spark作业提交脚本
- 5-5 将统计结果写入到MySQL中
- 5-6 统计结果写入到MySQL调优
- 5-7 Spark ETL到HBase优化之禁用WAL
- 5-8 Spark ETL到HBase的HFile思路
- 5-9 Spark产生HFile文件格式准备工作
- 5-10 Spark产生HFile整个流程实现并总结
-
第6章 实时项目实战
本章节讲解基于Spark和Redis的实时综合项目实战,从Spark Streaming整合Kafka对接出发,如何实现需求的功能以及如何对代码进行重构使得执行效率更好,掌握Redis在项目实战中的数据类型选型,以及如何将SparkStreaming处理完的数据写入到Redis中去。…
- 6-1 课程目录
- 6-2 项目背景
- 6-3 项目架构及处理流程
- 6-4 项目需求
- 6-5 开发环境准备及参数配置统一管理
- 6-6 Kafka部署及测试
- 6-7 Mock数据
- 6-8 发送数据到Kafka
- 6-9 SparkStreaming对接Kafka数据
- 6-10 功能实现之每天的粒度统计..1
- 6-11 功能开发之调优
- 6-12 功能实现小结
- 6-13 功能实现之每小时统计及代码重构
- 6-14 SparkStreaming对接Kafka offset管理
-
第7章 初识Alluxio
Alluxio是一个以内存为中心的虚拟分布式存储系统,统一数据访问和桥梁的计算框架和底层存储系统。应用程序只需要Alluxio就可以把访问存储在任何底层存储系统的数据连接。本章节将从Alluxio为我们带来的好处出发,再到Alluxio如何整合Hadoop以及Spark进行实操,并分享一些Alluxio在大公司中的使用案例。…
- 7-1 课程目录
- 7-2 概述
- 7-3 Spark应用存在的问题分析
- 7-4 Alluxio能为我们带来什么
- 7-5 Alluxio特点
- 7-6 在Spark实战项目中引入Alluxio
- 7-7 Alluxio部署
- 7-8 Alluxio文件系统命令行操作
- 7-9 Alluxio整合HDFS使用
- 7-10 Alluxio整合MapReduce使用
- 7-11 Alluxio整合Spark使用
- 7-12 Alluxio案例分享之在百度的使用
- 7-13 Alluxio案例分享之在去哪儿的应用
-
第8章 Spark优化
本章节将从Spark在生产上的最佳实践出发,和大家分享Spark的常用优化策略。
- 8-1 课程目录
- 8-2 调优之资源设置
- 8-3 调优之算子的合理选择
- 8-4 扩展之自定义排序一
- 8-5 扩展之自定义排序二(附带经典面试题)
- 8-6 扩展之自定义排序(隐式转换)
- 8-7 Spark Streaming调优之Kafka限速
- 8-8 Spark Streaming对接Kafka能真正做到仅消费一次吗
- 8-9 调优之序列化
- 8-10 调优之广播变量
-
第9章 (讨论群内直播内容分享)基于Spark定制ETL框架
了解Pipeline的处理方法,基于Spark外部数据源定制Spark ETL框架的思路及使用
- 9-1 Data Pipeline_x264
- 9-2 ETL中可能会遇到的问题_x264
- 9-3 (打标记处,3处听不清楚) Spark SQL DataSource API_x264
- 9-4 使用Spark SQL处理json数据_x264
- 9-5 基于Spark ETL框架的设计
- 9-6 基于Spark ETL框架的使用_x264
-
第10章 (讨论群内直播内容分享)Spark3新特性
Spark3是一个里程碑版的版本,其中包含很多新的特性,本次直播中主要带大家知晓新特性有哪些,以及讲解动态分区裁剪、外部数据源V2、自适应查询执行等相关知识。
- 10-1 Spark概述
- 10-2 Spark3.x新特性
- 10-3 DataSource API V2
- 10-4 动态分区裁剪
- 10-5 自适应查询执行