Python爬虫工程师从入门到进阶【已完结 MK325】

-
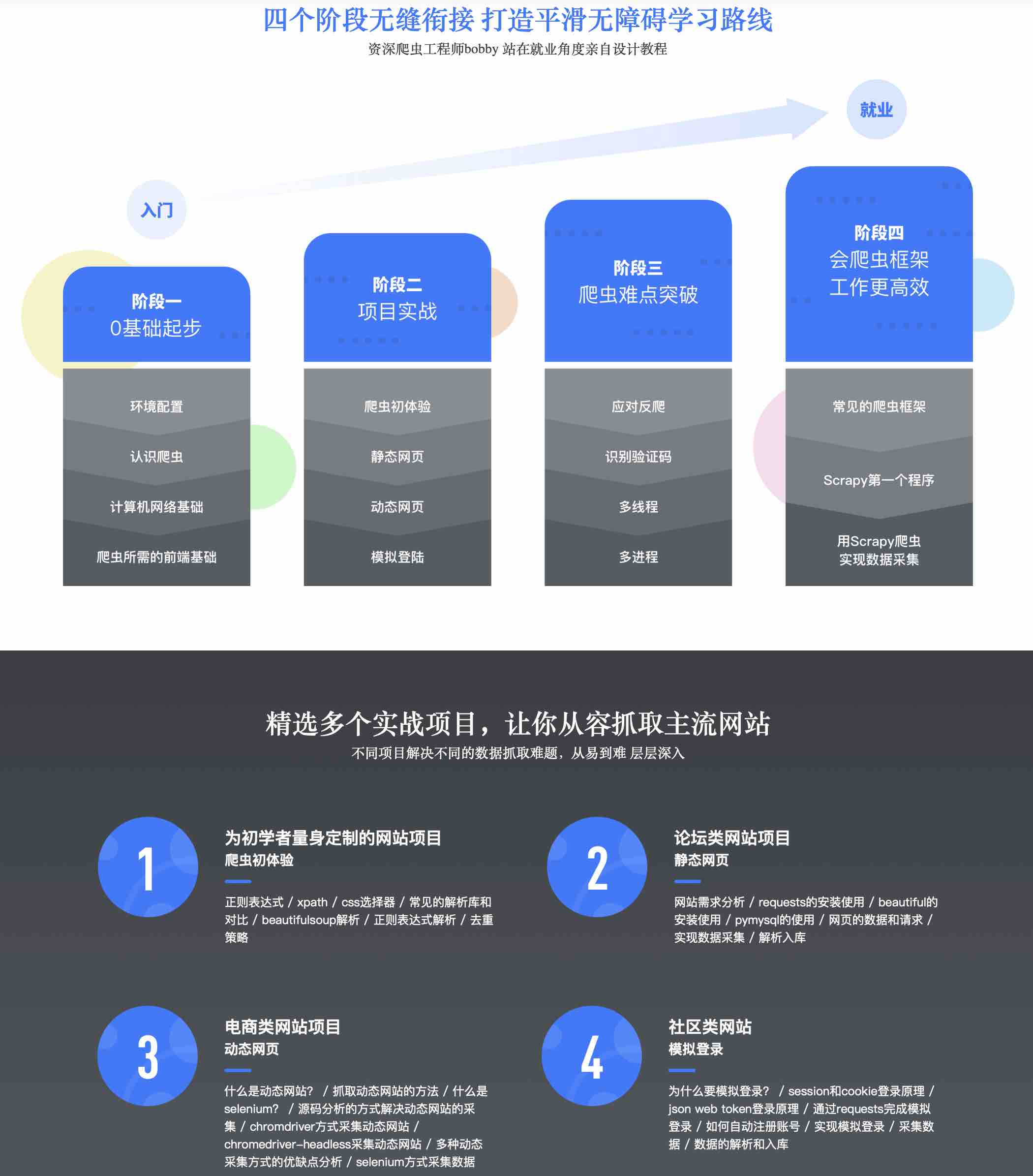
第1章 从零开始 系统入门python爬虫工程师-课程导学(提醒:购买后记得加入课程群)
这是一门专门为爬虫初学者打造的教程,从零起步的系统化教程,课程内容从理论到实践,一层一层深入讲解,尤其是课程实战环节:一步一步带你进行多场景项目实践 ,让你能够举一反三从容面对以后的数据抓取问题,最后关于就业部分,重点,难点,针对性讲解,轻松应对面试,最终达到就业水准。…
- 1-1 从零开始 系统入门python爬虫工程师-课程导学试看
-
第2章 彻底解决让人头疼的环境搭建问题 视频教程+文档补充 轻松帮你搞定!
本章节主要采用视频+文档的方式详细讲解如何在windows/linux/mac下安装和配置python、pycharm、mysql、navicat和虚拟环境。(学习的过程中遇到问题卡壳,可以及时在问答区提问和反馈,我们会积极针对性优化,让学习过程变得顺畅,帮您节约时间成本)…
- 2-1 python的安装
- 2-2 python的安装和配置 – linux
- 2-3 python的安装和配置 – mac
- 2-4 pycharm的安装和配置 (必看!!)
- 2-5 课程中用到的pycharm快捷键(必看!!!)
- 2-6 mysql和navicat的安装和使用
- 2-7 mysql和navicat的安装和配置 – linux
- 2-8 mysql和navicat的安装和配置 – mac
- 2-9 虚拟环境的安装和配置
- 2-10 虚拟环境的安装和配置 – linux
- 2-11 虚拟环境的安装和配置 – mac
-
第3章 我们从了解网络爬虫开始,重新认识爬虫。
在学习之前,首先知道我们为什么要学习爬虫,学习了课程之后我们到底能做什么?希望大家不要仅仅将思维局限在爬虫知识只能用来抓取数据,而是能帮我们做很多有趣且重复的工作。
- 3-1 爬虫能做什么?
- 3-2 Python网络爬虫需要学习的知识和解决的问题
- 3-3 爬虫是万能的吗?
-
第4章 爬虫工程师基本功–计算机网络协议基础
不论是爬虫方,还是去反爬的开发或者运维人员,都需要有计算机网络的相关知识,所以课程中我们单独设置了一个章节详细的讲解和爬虫相关的计算机网络的基础知识,这些知识是我们遇到问题后去分析和解决问题的理论基础。…
- 4-1 为什么我们需要学习计算机网络
- 4-2 一个完整的网络请求过程
- 4-3 ip地址和url详解 – 为什么网站一般不会封ip?
- 4-4 有哪些网络协议?
- 4-5 我们经常看到的tcp-ip协议是什么?试看
- 4-6 socket编程 – 客户端和服务端通信 – 1
- 4-7 socket编程 – 客户端和服务端通信-2
- 4-8 基于tcp自定义第一个协议 – 模拟qq服务器和客户端 – 1
- 4-9 基于tcp自定义第一个协议 – 模拟qq服务器和客户端 – 2
- 4-10 基于tcp自定义第一个协议 – 模拟qq服务器和客户端 – 3
- 4-11 正确认识http协议 – 1
- 4-12 正确认识http协议 -2
- 4-13 本章课后作业
-
第5章 爬虫工程师基本功–前端基础
一个web系统的建设基础是网络协议,但是数据的展示和交互确是由前端开发人员来完成的,所以了解前端知识也是我们遇到问题并分析问题的关键,具备一定的前端知识不论是作为后端开发人员还是爬虫开发人员必备的技能。
- 5-1 html、css和JavaScript之间的关系…1
- 5-2 浏览器的加载过程
- 5-3 dom树和JavaScript操作dom树
- 5-4 ajax、json和xml
- 5-5 动态网页和静态网页
- 5-6 GET、POST方法和Content-type详解
- 5-7 ajax方式提交表单数据
- 5-8 本章课后作业。
-
第6章 爬虫前置知识讲解&爬虫初体验
本章节涉及到开始实战爬虫之前需要了解到的前置知识,包括requests的简单使用以及解析方案的基础知识如:正则表达式、xpath和css选择器,本章节将会使用xpath和css选择器解析自定义的html结构,通过解析自定义的html结果去提取需要的元素…
- 6-1 爬虫采集方案分类
- 6-2 requests功能详解
- 6-3 正则表达式-基本语法
- 6-4 正则表达式 – python接口
- 6-5 beautifulsoup用法 – find方法试看
- 6-6 beautifulsoup用法 – 父子节点和兄弟节点获取
- 6-7 xpath基本语法 – 1
- 6-8 xpath基本语法 – 2
- 6-9 css选择器提取元素
-
第7章 项目实战1 – 论坛网站,实现静态网页数据抓取
本章节中我们将会细致全面的开始我们的第一个爬虫实战,包括需求分析、爬虫策略的制定、爬虫的解析和入库,在本章节中我们在介绍pymysql和peewee的简单使用后会对表结构进行设计
- 7-1 需求分析
- 7-2 pymysql的简单使用
- 7-3 peewee自动生成表_1
- 7-4 通过peewee对数据进行增、删、改、查…1
- 7-5 models表结构设计
- 7-6 分析和获取所有的版块 – 1
- 7-7 分析和获取所有的版块 – 2
- 7-8 论坛网站-反爬的分析
- 7-9 获取和解析列表页-1
- 7-10 获取和解析列表页 – 2
- 7-11 获取和解析详情页 – 1
- 7-12 获取和解析详情页 – 2
- 7-13 获取个人信息详情-1
- 7-14 获取个人信息详情 – 2
-
第8章 多线程和线程池编程 – 进一步改造爬虫
多线程和多进程编程不论在什么语言中都是非常重要的知识点而且属于难点,在python中也不例外,在实际工作中由于大量的多线程和多进程工作已经被我们使用的框架完成了,所以很多同学接触到多线程编程的机会并不多,爬虫是多线程开发的一个非常常见的应用场景,本章节将会介绍如何使用多线程的方式去改造之前的爬虫,进一步加…
- 8-1 并发和并行
- 8-2 多线程编程
- 8-3 python的GIL真的会导致多线程慢吗?
- 8-4 线程同步 – Lock
- 8-5 使用多线程重构csdn爬虫 – 1
- 8-6 使用多线程重构csdn爬虫 – 2
- 8-7 使用多线程和Queue重构csdn爬虫
- 8-8 进一步的思考 – 课后作业
- 8-9 ThreadPoolExecutor的基本功能
- 8-10 ThreadPoolExecutor线程池重构爬虫
-
第9章 项目实战2-电商网站,实现动态网网站的数据抓取
随着前端的工程化和反爬以及多端开发的需求,动态网站也变得越来越多,如果如何去分析和应对动态网站就是爬虫中一个非常常见的需求,本章节我们通过实战的方式来分析并完成一个动态网站的爬虫,本章节中我们将接触到动态网站最常用的手段selenium和chrome driver,通过selenium我们可以很容易的完成动态网站的数据采集。…
- 9-1 需求分析
- 9-2 表结构设计
- 9-3 chrome的f12后的调试工具栏介绍
- 9-4 京东的商品详情页接口分析
- 9-5 通过requests完成京东详情页数据的获取
- 9-6 selenium的安装和使用
- 9-7 通过selenium解析商品详情页 – 1
- 9-8 通过selenium解析商品详情页 – 2
- 9-9 通过selenium解析商品详情页 – 3
- 9-10 通过selenium解析商品详情页 – 4
- 9-11 通过selenium解析商品详情页 – 5
- 9-12 chromedirver的headless模式和设置不加载图片
- 9-13 课后作业和总结
-
第10章 实战项目3-社区网站,实现模拟登陆和验证码
除了前面的动态网站以外,大量网站为了保护数据,需要用户登录以后才能访问网站,对于这种数据的采集除了需要我们具备前面的知识以外,对模拟登录的需求也就变成了一项基本技能,在本章节中我们将从后端登录的原理来讲解后端登录的原理是如何实现的,在本章节中我们也会解决模拟登录过程中最常见的问题 – 验证码…
- 10-1 章节目标和为什么需要模拟登录
- 10-2 模拟登录的原理- session和cookie的原理
- 10-3 requests模拟登录豆瓣
- 10-4 将cookie保存到文件中并从文件中读取cookie
- 10-5 selenium模拟登录豆瓣
- 10-6 滑动验证码识别 和selenium模拟登录B站 – 1
- 10-7 滑动验证码识别 和selenium模拟登录B站 – 2
- 10-8 滑动验证码识别 和selenium模拟登录B站 – 3
- 10-9 第三方验证码识别服务商推荐camproj
- 10-10 课后作业和总结
-
第11章 先懂反爬再应对反爬
大量的网站为了防止数据被爬和防止爬虫对网站造成的访问压力,都会加大对爬虫的限制,所以想要采集到有价值的数据,反爬就是一道必须绕过的门槛,本章节将介绍常用的反爬技术以及应对方法,如ip代理和user-agent的设置等。通过本章的学习大家将了解到如何应对目标网站的反爬。…
- 11-1 反爬和反反爬
- 11-2 常见的反爬方案
- 11-3 通过user-agent反爬
- 11-4 通过收费的代理ip绕过反爬 – 1
- 11-5 通过收费的代理ip绕过反爬 – 2
- 11-6 通过一个实际的案例分析一下反爬策略是什么
-
第12章 学会用框架,scrapy实现快速开发爬虫
通过前面前面的学习,大家都掌握了如何去完成一个高质量的爬虫,但是在实际的开发中由于爬虫会有很多通用的问题已经被爬虫框架解决,所以直接使用已经成熟的爬虫框架就是很多实际项目的首选,本章节我们将接触到python中最强大的爬虫框架-scrapy,通过本章节的学习大家将学会如何去快速的搭建一个高效的爬虫系统。…
- 12-1 新建scrapy项目
- 12-2 通过pycharm调试scrapy
- 12-3 编写spider的逻辑
- 12-4 item和pipeline
- 12-5 scrapy集成随机useragent和ip代理
-
第13章 帮你规划一条通往高级爬虫工程师的进阶之路
爬虫是一个需要不断深入和变化的过程,本课程是爬虫的入门课程,后续的学习还要我们继续加深对爬虫的学习,本章节将会给大家引申出一些更加深入的话题,大家可以沿着这些思路去进一步的学习。
- 13-1 课程总结
- 13-2 成为高级爬虫工程师的学习建议