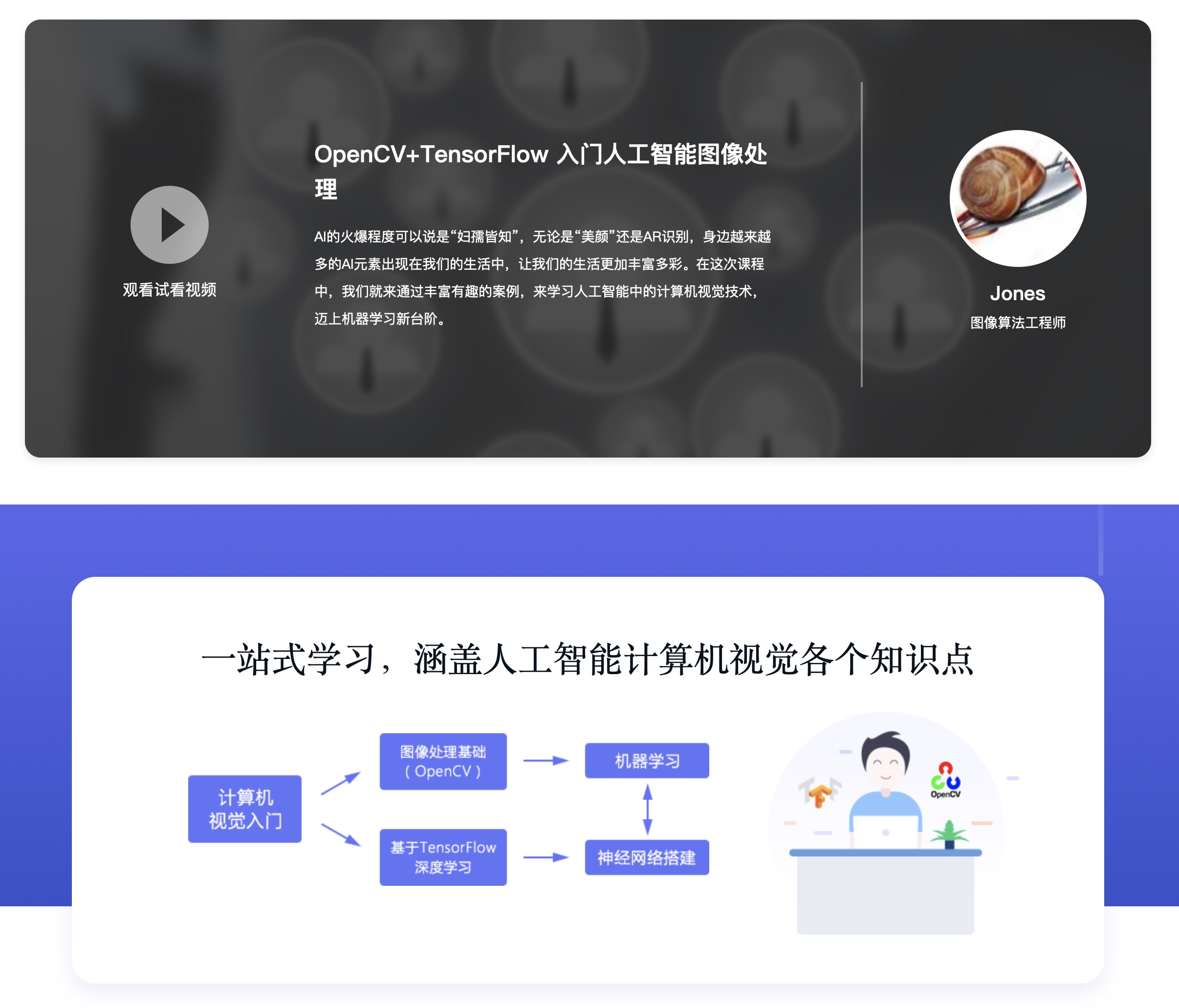
Python网络爬虫与信息提取视频教程
快讯:本课程是国家精品在线开放课程“Python网络爬虫与数据分析”的上半部分,当前为第7次开课,欢迎大家前来学习!
—— 为什么要学习网络爬虫?
—— 因为数据都在网上,先要爬下来才能挖掘淘金 …
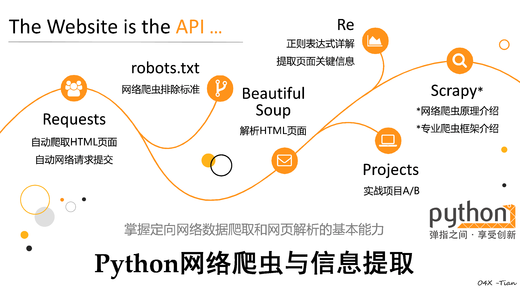
“The website is the API.” (网页即接口)网络爬虫是获取数据的必备本领,不要犹豫!
本课程面向具有Python编程基础的各类学习者,讲解利用Python语言爬取网络数据并提取关键信息的技术和方法,帮助学习者掌握定向网络数据爬取和网页解析的基本能力。
本课程介绍Python计算生态中最优秀的网络数据爬取和解析技术,具体讲授构建网络爬虫功能的两条重要技术路线:requests-bs4-re和Scrapy,所讲述内容广泛应用于Amazon、Google、PayPal、Twitter等国际知名公司。课程内容是进入大数据处理、数据挖掘、以数据为中心人工智能领域的必备实践基础。
本课程教学内容包括:
· Python第三方库Requests,讲解通过HTTP/HTTPS协议自动从互联网获取数据并向其提交请求的方法;
· Python第三方库Beautiful Soup,讲解从所爬取HTML页面中解析完整Web信息的方法;
· Python标准库Re,讲解从所爬取HTML页面中提取关键信息的方法;
· Python第三方库Scrapy,介绍通过网络爬虫框架构造专业网络爬虫的基本方法。
本课程希望传递“理解和运用计算生态”的理念,重点培养学习者运用当代最优秀第三方专业资源,快速分析和解决问题的能力。”人生苦短,不要刀耕火种“,嵩老师教你直面问题和需求,用最好的工具解决它!
本课程是国家精品在线开放课程“Python网络爬虫与数据分析”课程的上半部分。“Python网络爬虫与数据分析”课程由“Python网络爬虫与信息提取”和“Python数据分析与展示”两门MOOC课程组成,完整地讲解了数据获取、清洗、统计、分析、可视化等数据处理周期的主要技术内容,培养计算思维、数据思维及采用程序设计方法解决计算问题的实战能力技术。

![[大课程] — Python全栈工程师2020【已完结 28G】](https://rurucode.oss-cn-beijing.aliyuncs.com/2020/12/1609251420-c4ca4238a0b9238.jpg)